Azure Form Recognizer is one of Cognitive Services that uses machine learning to extract information from form documents such as invoices, receipts, etc. The service performs OCR (Optical Character Recognition) to extract text and structure to be used in model training and prediction.
The service, consumed via REST API, offers the prebuilt (pre-trained) and custom models. At the time of this writing, the prebuilt model is only for US sales receipts. (More should come soon.) The custom models, which train our own data, offer two ways to perform training – train without and with labels.
Model training without labels uses unsupervised learning (no manual inputs from users) while the training with labels uses supervised learning. This post will show differences between the two in creating a custom model from the perspective of how to use them and results using the same training and test data.
| Train custom model WITHOUT labels | Train custom model WITH labels |
| Unsupervised learning | Supervised learning |
| Auto-discover keys and associated values | Manually create keys (tags) and label where associated values are |
| Works well with the simple same-formatted form | Works better with varied formatted form |
Using the provided invoice sample, I’ve uploaded all five invoice files to Azure storage and obtained SAS (Shared Access Signature) URL.
Starting with training a model without labels, I use the original train script to run. Its output is a mode ID.
For prediction, I modified the original analyze script a bit to display all key-value pairs Form Recognizer can identify as well as their confidence values (0-1 with 0 the least confidence, 1 the most.) I highlighted what I changed in the script below.
########### Python Form Recognizer Async Analyze #############
import json
import time
from requests import get, post
# Endpoint URL
endpoint = "https://frecog2.cognitiveservices.azure.com/"
apim_key = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
model_id = "xxxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx"
post_url = endpoint + "/formrecognizer/v2.0-preview/custom/models/%s/analyze" % model_id
source = "C:\\Users\\ichamma1\\Downloads\\sample_data\\Test\\Invoice_6.pdf"
params = {
"includeTextDetails": True
}
headers = {
# Request headers
'Content-Type': 'application/pdf',
'Ocp-Apim-Subscription-Key': apim_key,
}
with open(source, "rb") as f:
data_bytes = f.read()
try:
resp = post(url = post_url, data = data_bytes, headers = headers, params = params)
if resp.status_code != 202:
#print("POST analyze failed:\n%s" % json.dumps(resp.json()))
quit()
print("POST analyze succeeded:\n%s" % resp.headers)
get_url = resp.headers["operation-location"]
except Exception as e:
print("POST analyze failed:\n%s" % str(e))
quit()
n_tries = 15
n_try = 0
wait_sec = 5
max_wait_sec = 60
while n_try < n_tries:
try:
resp = get(url = get_url, headers = {"Ocp-Apim-Subscription-Key": apim_key})
resp_json = resp.json()
if resp.status_code != 200:
print("GET analyze results failed:\n%s" % json.dumps(resp_json))
quit()
status = resp_json["status"]
if status == "succeeded":
print("Analysis succeeded:\n%s" % json.dumps(resp_json))
#print("Analysis succeeded:\n%s" % json.dumps(resp.json(), indent=4))
Result = resp_json["analyzeResult"]["pageResults"][0]["keyValuePairs"]
ResultCount = len(resp_json["analyzeResult"]["pageResults"][0]["keyValuePairs"])
for i in range(ResultCount):
print(Result[i]["key"]["text"], Result[i]["value"]["text"], " || Confidence: ", Result[i]["confidence"])
quit()
if status == "failed":
print("Analysis failed:\n%s" % json.dumps(resp_json))
quit()
# Analysis still running. Wait and retry.
time.sleep(wait_sec)
n_try += 1
wait_sec = min(2*wait_sec, max_wait_sec)
except Exception as e:
msg = "GET analyze results failed:\n%s" % str(e)
print(msg)
quit()
print("Analyze operation did not complete within the allocated time.")
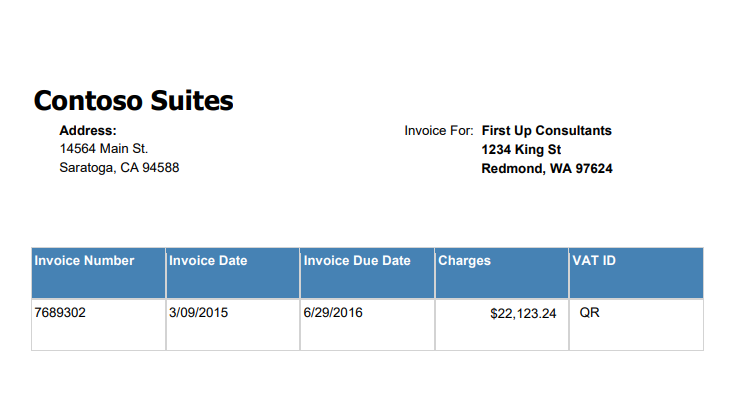
We can tell from the result is that Form Recognizer automatically detects keys (label above or left of the value) and associated values from all possible locations. This is very convenient if all of our document is in the same formats.
Address: 14564 Main St. Saratoga, CA 94588 || Confidence: 0.86 Invoice For: First Up Consultants 1234 King St Redmond, WA 97624 || Confidence: 1.0 Invoice Number 7689302 || Confidence: 1.0 Invoice Date 3/09/2015 || Confidence: 1.0 Invoice Due Date 6/29/2016 || Confidence: 1.0 Charges $22,123.24 || Confidence: 1.0 VAT ID QR || Confidence: 1.0 Page 1 of || Confidence: 0.86 __Tokens__1 Contoso Suites || Confidence: 1.0 __Tokens__2 1 || Confidence: 1.0
If we have various formats of documents and want to train them in the same model, this may pose a challenge because the key texts will be different. We will have to do some post works to handle them.
Fortunately, for various formats, we can use the sample labeling tool to control where we’d like Form Recognizer to look for information.
The instruction on how to install and configure the sample labeling tool is here. Once installed, it is very easy to proceed with labeling, training, and even testing (predicting) trained models.
Here are some high-level steps:
- Create a connection with to connect to SAS URL. This will allow the labeling tool to access training sample data. Make sure Read, Write, Delete, and List permissions are granted.
- Create a new project which will include the connection created in the previous step and Form Recognizer endpoint & key.
- Create all tags (from the top right section.)
- If prompted, run the OCR on all documents. Note that the yellow highlights are text outputs from OCR.
- Simply highlight the texts and then click on the corresponding tag.
- Repeat for all training samples.

Once labeling all, click to train the model. Make note of the Model ID to be used later.

We can also validate the model by uploading a test file.

Similar to the prediction script for without label, I modified the original analyze script to display tag, predicted value, and confidence number.
########### Python Form Recognizer Async Analyze #############
import json
import time
from requests import get, post
# Endpoint URL
endpoint = "https://frecog2.cognitiveservices.azure.com/"
apim_key = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
model_id = "xxxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx"
post_url = endpoint + "/formrecognizer/v2.0-preview/custom/models/%s/analyze" % model_id
source = "C:\\Users\\ichamma1\\Downloads\\sample_data\\Test\\Invoice_6.pdf"
params = {
"includeTextDetails": True
}
headers = {
# Request headers
'Content-Type': 'application/pdf',
'Ocp-Apim-Subscription-Key': apim_key,
}
with open(source, "rb") as f:
data_bytes = f.read()
try:
resp = post(url = post_url, data = data_bytes, headers = headers, params = params)
if resp.status_code != 202:
#print("POST analyze failed:\n%s" % json.dumps(resp.json()))
quit()
print("POST analyze succeeded:\n%s" % resp.headers)
get_url = resp.headers["operation-location"]
except Exception as e:
print("POST analyze failed:\n%s" % str(e))
quit()
n_tries = 15
n_try = 0
wait_sec = 5
max_wait_sec = 60
while n_try < n_tries:
try:
resp = get(url = get_url, headers = {"Ocp-Apim-Subscription-Key": apim_key})
resp_json = resp.json()
if resp.status_code != 200:
print("GET analyze results failed:\n%s" % json.dumps(resp_json))
quit()
status = resp_json["status"]
if status == "succeeded":
print("Analysis succeeded:\n%s" % json.dumps(resp_json))
#print("Analysis succeeded:\n%s" % json.dumps(resp.json(), indent=4))
Result = resp_json["analyzeResult"]["documentResults"][0]["fields"]
#-------------------------------------------------------------
MerchantName = ""
if ("Merchant Name" not in Result):
print("Merchant Name: Not Found")
else:
if ("valueString" not in str(Result["Merchant Name"])):
MerchantName = Result["Merchant Name"]["text"]
else:
MerchantName = Result["Merchant Name"]["valueString"]
print("Merchant Name: " + MerchantName + " || Confidence: " + str(Result["Merchant Name"]["confidence"]))
#-------------------------------------------------------------
MerchantAddress = ""
if ("Merchant Address" not in Result):
print("Merchant Address: Not Found")
else:
if ("valueString" not in str(Result["Merchant Address"])):
MerchantAddress = Result["Merchant Address"]["text"]
else:
MerchantAddress = Result["Merchant Address"]["valueString"]
print("Merchant Address: " + MerchantAddress + " || Confidence: " + str(Result["Merchant Address"]["confidence"]))
#-------------------------------------------------------------
InvoiceDate = ""
if ("Invoice Date" not in Result):
print("Invoice Date: Not Found")
else:
if ("valueString" not in str(Result["Invoice Date"])):
InvoiceDate = Result["Invoice Date"]["text"]
else:
InvoiceDate = Result["Invoice Date"]["valueString"]
print("Invoice Date: " + InvoiceDate + " || Confidence: " + str(Result["Invoice Date"]["confidence"]))
#-------------------------------------------------------------
InvoiceNumber = ""
if ("Invoice Number" not in Result):
print("Invoice Number: Not Found")
else:
if ("valueString" not in str(Result["Invoice Number"])):
InvoiceNumber = Result["Invoice Number"]["text"]
else:
InvoiceNumber = Result["Invoice Number"]["valueString"]
print("Invoice Number: " + InvoiceNumber + " || Confidence: " + str(Result["Invoice Number"]["confidence"]))
#-------------------------------------------------------------
InvoiceAmount = ""
if ("Invoice Amount" not in Result):
print("Invoice Amount: Not Found")
else:
if ("valueString" not in str(Result["Invoice Amount"])):
InvoiceAmount = Result["Invoice Amount"]["text"]
else:
InvoiceAmount = Result["Invoice Amount"]["valueString"]
print("Invoice Amount: " + InvoiceAmount + " || Confidence: " + str(Result["Invoice Amount"]["confidence"]))
quit()
if status == "failed":
print("Analysis failed:\n%s" % json.dumps(resp_json))
quit()
# Analysis still running. Wait and retry.
time.sleep(wait_sec)
n_try += 1
wait_sec = min(2*wait_sec, max_wait_sec)
except Exception as e:
msg = "GET analyze results failed:\n%s" % str(e)
print(msg)
quit()
print("Analyze operation did not complete within the allocated time.")
With the labeling option, we control the key (tag) text and where the value should be by labeling it. Note that this is not static fixed-position training. Form Recognizer is smart enough to figure out the variable-length text like various length in decimal number.
Merchant Name: First Up Consultants || Confidence: 1.0 Merchant Address: 1234 King St Redmond, WA 97624 || Confidence: 0.995 Invoice Date: 3/09/2015 || Confidence: 1.0 Invoice Number: 7689302 || Confidence: 1.0 Invoice Amount: $22,123.24 || Confidence: 1.0
I’ve tried training on various invoice formats (with 5-6 samples each) in the same model. The prediction is still working quite well.
This label option is very helpful, in comparison with the without-label option, in some of these cases:
- Various key texts such as Sales Order #, SO#, SO, etc. in different document formats
- No key text
- The key text is not positioned next to the value text
One of the minor inconveniences I’ve seen is that all predicted values are in the string formats, for example, in different invoices, the invoice dates may be 10/11/2019, 11-12-2019, or 31/12/2019. If you need to convert this to date, it has to be done outside with some text processing steps. I’ve been informed by the product team that the value type will be introduced. This may eliminate a need for post-processing.
For end-to-end flow, you can use Power Automate for managing pre- and post-task workflows. At the time of this writing, only Form Recognizer v1 connector is available.
References: